Four years after OpenAI’s Whisper transformed speech recognition, and amid a wave of breakthroughs from ElevenLabs, Deepgram, Cartesia, and others, Voice AI has definitively arrived. There are now hundreds of voice-powered applications emerging across every vertical: sales, healthcare scribing, contact centres, logistics, telecoms, debt collection, and beyond – as we’ve previously written. Every human voice interaction is a candidate for a voice AI interaction, and as such, there is a massive market up for grabs. In contact centres alone, Gartner estimates that there is $80b of human labour that could be disrupted by voice AI agents (Gartner, 2022).
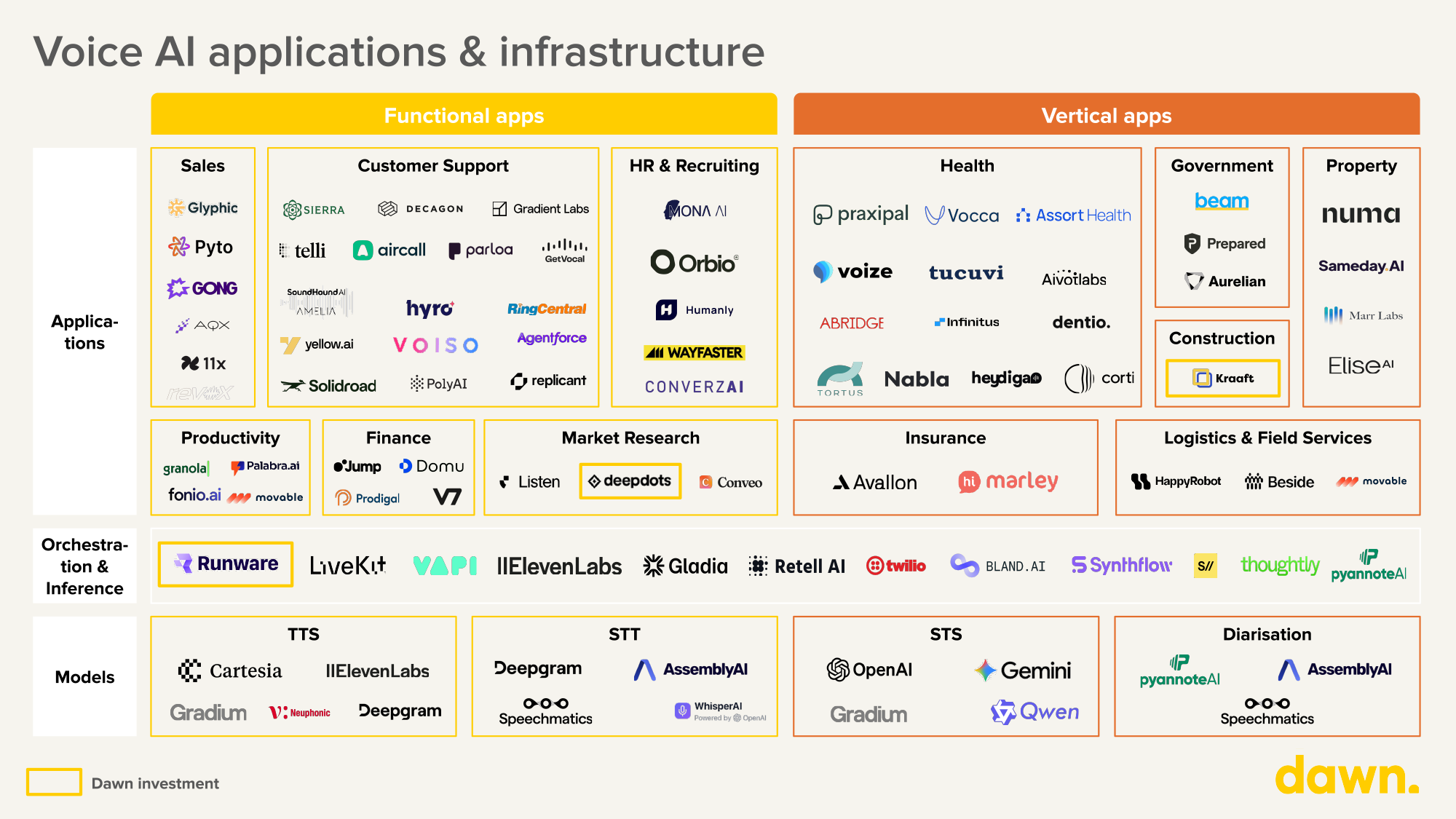
(Figure 1: Voice AI Market Map)
However, despite this momentum, voice AI is not yet ubiquitous. Almost every builder we speak to in the space tells us the same thing: something is still broken in voice infrastructure. The technology is potentially transformative for customers, but remains clunky for builders.
How are developers building Voice AI applications today? At Dawn, over the past year, we’ve met with over 50 founders and engineering teams building across the voice stack. In this piece, we share our thesis on what’s broken, why it matters, and where we still see the opportunity.
How are developers building Voice AI applications today?
To understand what needs to evolve with voice AI, it’s important to understand how many of these applications are being built today.
Despite the emergence of native speech-to-speech (S2S) models – GPT-4o’s Realtime API, Gemini 2.5 Flash Live – the vast majority of production voice applications today are still built as cascaded pipelines: separate STT, LLM, and TTS models stitched together with orchestration logic. Some S2S models deliver the latency enterprises need, but at 2-10x the cost of pipeline approaches ($0.50-$1.50 per minute versus $0.10-$0.20 for managed pipelines) (Skywork AI, 2025), and with less flexibility for customisation and limited fine-tuning support. Moreover, their latency advantages largely disappear over traditional PSTN phone networks.
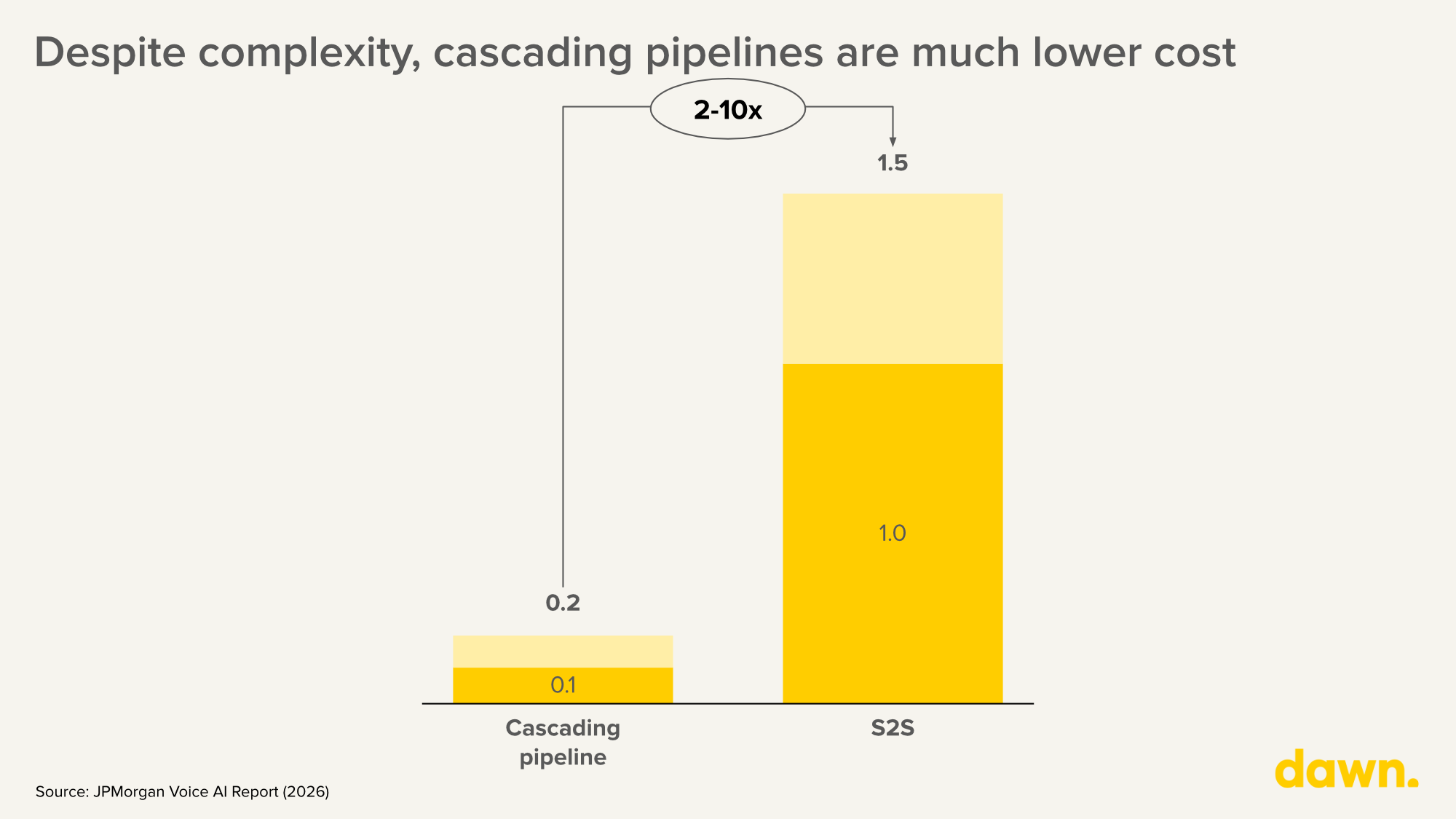
(Figure 2: Delta between managed pipeline and S2S in cost per minute)
As a result, engineering teams are spending months on plumbing. Abstraction layers like LiveKit (open-source, flexible, but significant implementation effort) and VAPI (turnkey, telephony-optimised, but limited backend control) are helping, but developers building voice as a core product feature consistently told us that getting to production quality still requires deep investment in orchestration, interruption handling, turn-taking, and failover.
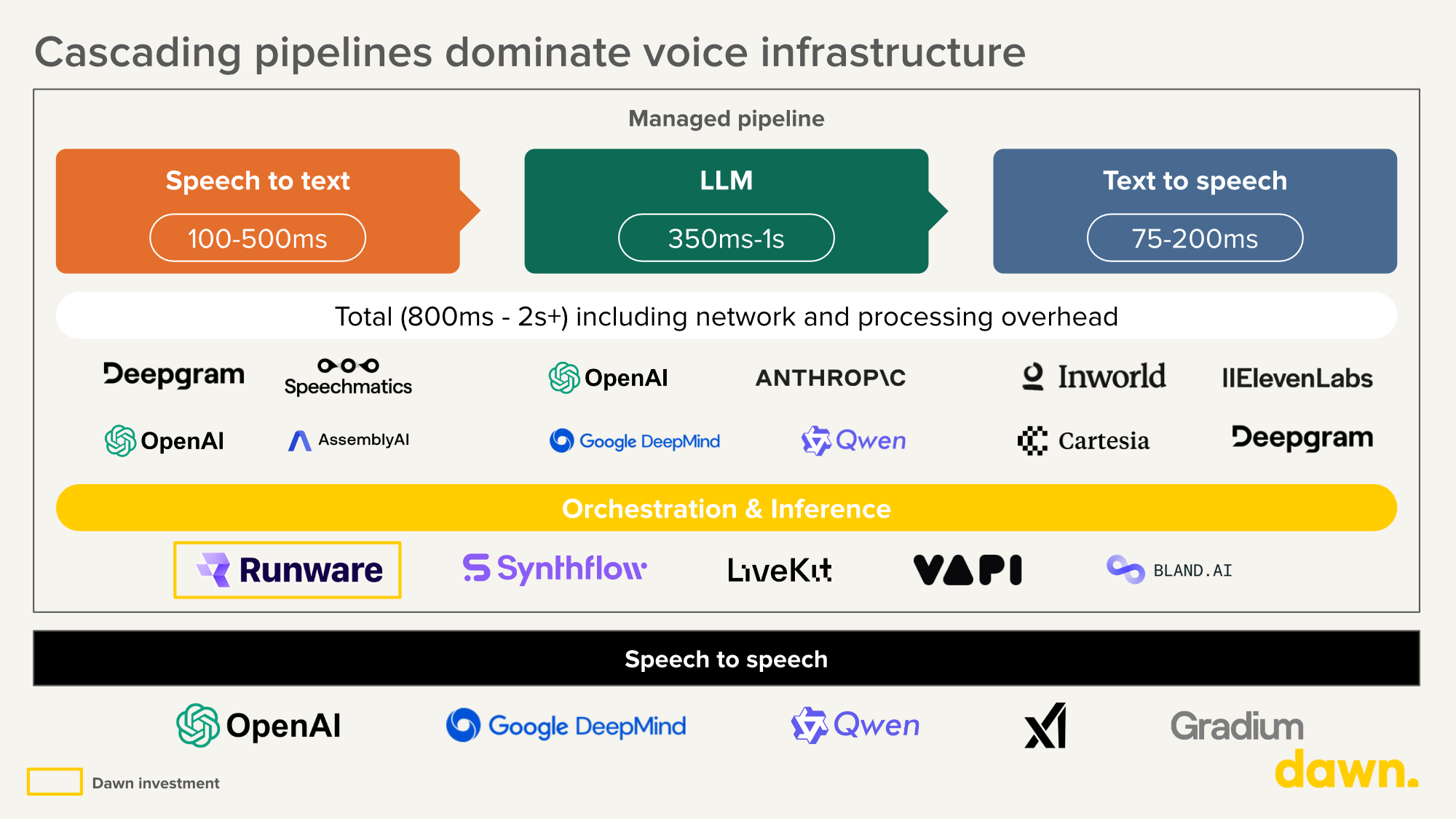
(Figure 3: Managed pipeline breakdown)
The economics: when will voice AI technology be “worth it”?
The cost case for voice AI is relatively obvious. An onshore US contact centre agent costs $28–$40 per hour. A fully managed voice AI pipeline costs $3–$9 per hour, a 70–90% reduction (Outsource Consultants, 2025). The arithmetic is compelling for onshore, but the gap narrows significantly against offshore labour, which costs $6–$9 per hour.
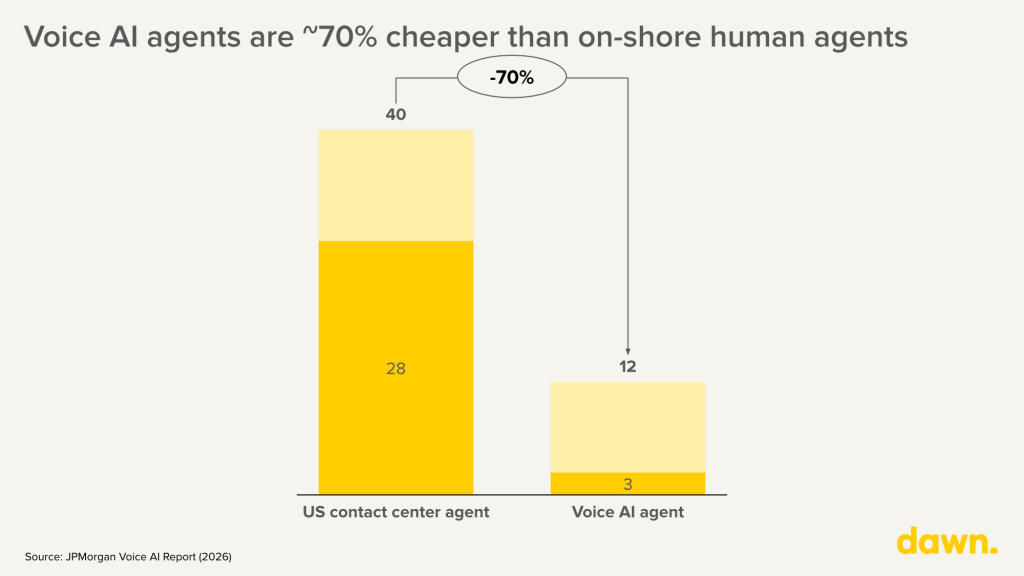
(Figure 4: Contact center agent vs. managed pipeline)
But the real driver of adoption isn’t the spreadsheet. Contact centres have been structurally broken for years: high attrition, inconsistent quality, missed revenue from abandoned calls. Incremental optimisation has failed to fix it. Voice AI doesn’t quit, doesn’t need onboarding, and scales from one concurrent call to a thousand. We’ve illustrated one US call centre example below:
(Figure 5: The impact of AI agents on a call center’s bottom line, $m)
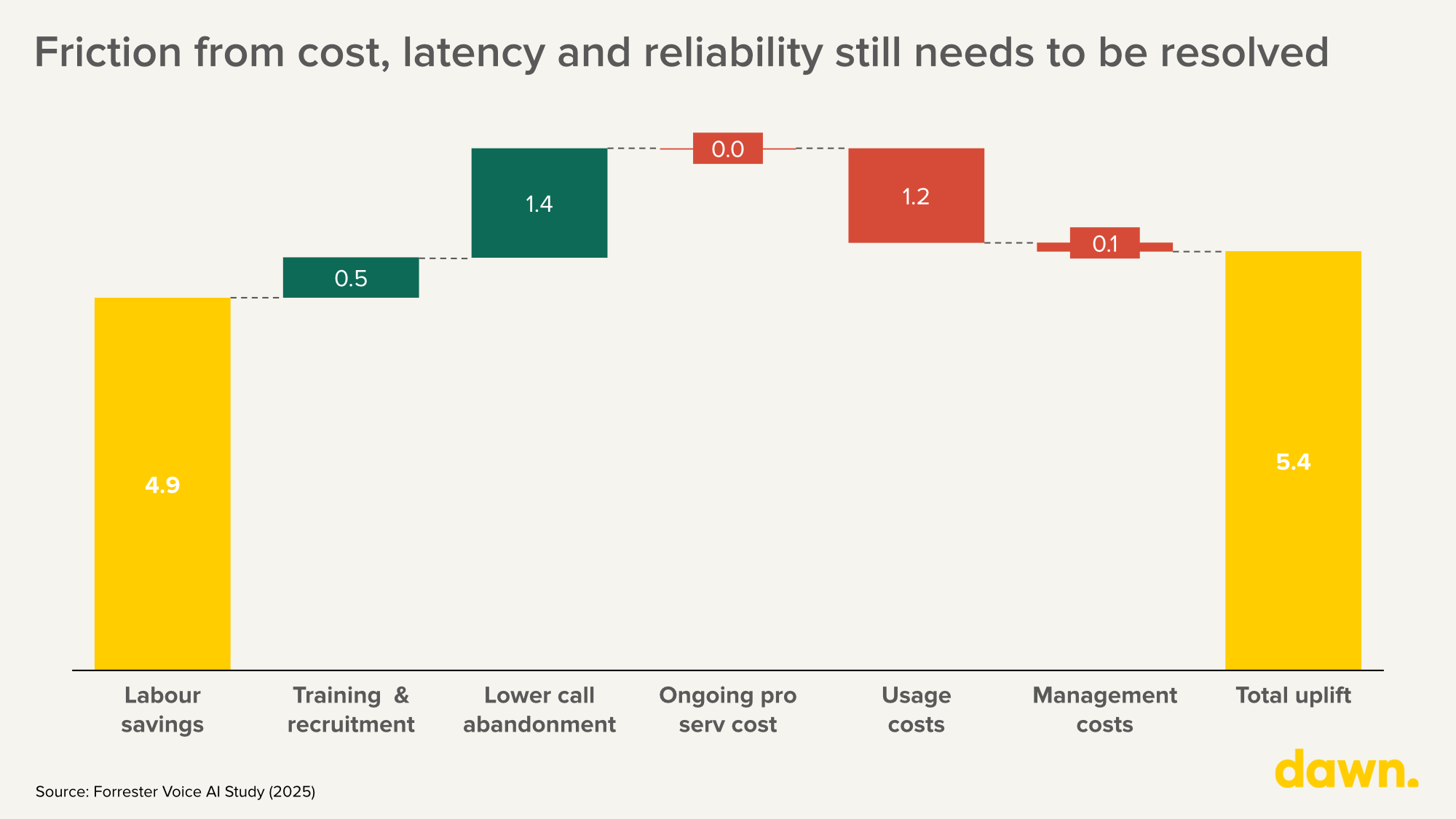
So, the real question is no longer whether it is economical for voice AI to replace human agents for routine interactions, but how fast the remaining friction in quality, latency, and reliability can be resolved, so that voice agents can handle the vast majority of calls rather than just the routine ones.
So what needs to be fixed?
Latency: the uncanny pause
As a result of cascading voice pipelines, latency remains a critical concern for voice Ai applications. Human conversation operates within a c.200ms response window (PNAS, Fast response times signal social connection in conversation). Today, most production voice agents today sit at 800ms to 2 seconds. That pause – even at 500ms – immediately signals “machine” to the user. The best cascaded pipelines achieve ~510ms end-to-end (100ms STT + 320ms LLM + 90ms TTS), still double the human conversational norm of ~230ms (Introl, 2025). For enterprise voice agents handling customer service or sales calls, this gap is the difference between adoption and abandonment.
As one builder puts it:

Latency is something the entire industry has to keep focus on, and the hard part is that averages lie! Even P90 isn’t enough often, one bad turn in a three-minute call can kill the whole conversation. You have to be perfect for the entire call… we run racing models’ for most use cases, so we call multiple providers and models in parallel and take the fastest good response. It’s significantly more expensive, but customer experience comes first.
Interestingly, we also learned from many voice experts that as voice pipeline latency compresses toward human norms, the bottleneck emerging is reasoning and tool execution. When a voice agent needs to query a database, execute a web search, or reason through a complex request, latency jumps from hundreds of milliseconds to full seconds, dwarfing any gains from faster STT or TTS. The most promising approaches don’t try to eliminate this delay but mask it using contextual fillers (“by the way, did you know there’s a festival in Tokyo this week?”) or natural conversational holds that create value during the wait. This is also shifting the engineering challenge from raw speed to conversational design.
Turn-taking: the harder problem hiding behind latency
Latency gets the headlines, but multiple builders we spoke to argued that the more fundamental conversational problem is turn-taking: knowing when the user has finished speaking, when to interrupt, when to hold, and when to force a turn. Raw response speed matters less than getting the conversational rhythm right.
The distinction is subtle but important. A 300ms pause before a response feels natural if the agent’s timing is right. A 100ms response that cuts across the user mid-sentence feels broken. The core challenge is voice activity detection in messy, real-world conditions, distinguishing a genuine end-of-turn from a breath, a background voice, or a momentary pause while the caller thinks. Miss a turn and the conversation stalls. Jump in too early and the agent talks over the user. Both destroy trust faster than a slow response ever would.
This is also where the trade-off between latency optimisation and natural conversation becomes explicit. Aggressive latency reduction can actually make turn-taking worse by triggering premature responses. The builders achieving the best conversational quality are optimising for the rhythm of the exchange, not just the speed of each individual response.
In most conversations I have with other CTOs in the voice AI space, latency is rarely the critical factor for the end user. Most people are actually fine with longer pauses than we assume. The harder problem is turn-taking: when the user stops speaking, how to distinguish that from background noise, when to override, when there’s a missed turn, when to force a turn. That conversational dynamic is the harder problem
Cost still remains prohibitive at scale
A fully managed voice AI pipeline costs $0.10-$0.20 per minute, or $6-$12 per hour. High-quality TTS from ElevenLabs alone can run ~$6 per hour of generated audio. While this may work for an expensive contact centre in the developed world, it is still not meaningfully cheaper than an offshore centre, or valuable for a consumer app with razor-thin margins. Multiple founders cite $1 per hour as the threshold that would unlock e-commerce, gaming, and consumer use cases. Open-source models like Qwen3-TTS (released January 2026) are rapidly closing the quality gap at a fraction of the cost when self-hosted ($0.012/min) (Softcery, 2025), but the fully integrated stack – with reliability, monitoring, and telephony – remains expensive.
With our Sonic Inference Engine (r), we deliver high-quality voice AI at 10x lower cost and milliseconds latency, alongside video and image models. At this level, even a one-cent reduction in inference cost doesn’t just improve margins, it unlocks entirely new markets and use cases that only we can serve.
Noisy environments and diarisation: the real-world accuracy gap
Almost every builder in voice talks about how hard it is to deliver reliable performance outside controlled environments. Background noise, overlapping speech, accents, and domain-specific terminology degrade accuracy sharply. Speaker diarisation, separating who said what, remains especially painful. State-of-the-art systems achieve 5-8% diarisation error rate on clean benchmarks but 15-25% on challenging real-world data (pyannote benchmark, 2025). Companies like pyannote are pushing the frontier (6.6% DER on English, 28% better than open-source alternatives), but the accuracy levels that regulated industries require are not consistently achieved in noisy, multi-speaker, multilingual settings.
We really shine in the most challenging acoustic conditions. Handling spontaneous, in-the-wild, multi-speaker conversational speech (with cross-talk, interruptions, and short backchannels) remains very hard.
Real-time personalisation: stateless by default
True voice personalisation – identifying who is on the line in real time and tailoring the interaction to their history, preferences, and context – requires deep CRM integration, identity verification, and sub-second context retrieval. Most voice deployments today are stateless: each interaction starts from zero. Enterprise buyers in banking and telecommunications consistently flag this as the gap between current capabilities and their vision of AI-powered customer relationships.
There is a path from automated voicemail to real-time voice sales agents for example, but the personalisation layer, knowing the caller, pulling their account context, adapting the conversation, is the hardest part to build.
Voice agents meet enterprise reality
Latency and cost dominate the infrastructure conversation, but the enterprise buyers and vertical builders we speak to increasingly point to a different bottleneck: context.
Voice systems that operate in isolation, disconnected from the workflows and systems of record around them, struggle to deliver the accuracy, traceability, and control that production environments demand. In healthcare, every interaction must align with the patient’s EHR. In financial services, it must map to the customer’s account history and compliance requirements. The voice interface is only as useful as the context it can access. It is for this reason that we see a huge opportunity for vertical voice applications to own all interactions around the customer. Every founder we spoke to who was building a vertical application agreed:
Latency matters, but autonomy matters more. We run a pipeline because our agents are built to act – pull context, trigger workflows, write to systems of record – not just respond. The winners in voice AI application won’t be those with the most natural-sounding voices alone, but those most deeply embedded in a company’s operations. Voice is the interface while context and autonomous action is the product
“Latency and cost are important, but the real challenge in voice AI is building systems that can operate reliably within complex, real-world workflows where accuracy and control are critical.
In healthcare, the value isn’t in the plumbing. It’s in things like recognising that a caller is due for their check-up and folding it into the booking with the right doctor at the right time. A year ago, 80% of our engineering time went into pipeline work. Today it’s closer to 20%. Speech-to-speech is changing the build calculus entirely. The winners will be the ones who reinvest that time into learning the industry and the workflows deeply, not perfecting the stack.
What will it take? A few bets on what we think will change the game for Voice AI
We don’t think the voice AI market is waiting for a single breakthrough. It’s waiting for multiple compounding improvements – and for builders who can assemble them into products that work end-to-end. Here’s where we think the winners will emerge:
First, we think S2S models will reach cost parity with pipelines within 18 months, and the cascaded architecture will become legacy. The deflationary curve in voice models is following the same trajectory as text LLMs: GPT-4 launched at c.$45 per million tokens (Nebuly, 2026); comparable inference is now available for under $3 (OpenAI, 2026). We expect S2S costs to follow a similar path as OpenAI, Google, and open-source alternatives compete on price and efficiency (Qwen3-TTS already delivers near-ElevenLabs quality at a fraction of the cost, for example).
S2S pricing is collapsing faster than anyone predicted. OpenAI’s Realtime mini tier now costs as little as $0.02-$0.04 per minute for audio alone (OpenAI, 2026), down from $0.30 per minute at launch in late 2024. For short interactions, S2S is already cheaper than most managed pipelines. For longer conversations, text token accumulation still inflates costs, but the trajectory is clear. When S2S reaches ~$0.10/min, the engineering complexity of managing multi-component pipelines will no longer be justified for most use cases. The companies best positioned are those building on flexible architectures that can migrate seamlessly from pipelines to S2S as economics shift.
But S2S may itself be a transitional architecture. Full duplex models, which speak and listen simultaneously rather than alternating turns, solve the conversational robustness problems that even the best S2S models cannot. Gradium’s recently published MoshiRAG (April 2026) demonstrates one path: a lightweight full duplex conversational interface that asynchronously queries powerful text LLMs for complex reasoning, preserving both the naturalness of full duplex and the modularity that builders rely on in pipelines today.
Even the best speech-to-speech models struggle with backchanneling, including interruptions with no intention to interrupt. It makes the conversation painful. What we invented at Gradium is full duplex: it’s always on. The model can speak at any moment, it listens all the time, you can talk over it, it can interrupt you, it can ask for clarification. That dynamic is the only way you can have human-level conversation.
Second, the orchestration layer will consolidate, and the winners will solve the hard edge cases, not the happy path. The current fragmentation – LiveKit for flexibility, VAPI for speed, Retell for enterprise, Bland for telephony, Layercode for existing backend integration – is unsustainable. As S2S models reduce the need for multi-component stitching, orchestration will increasingly mean solving interruption handling, background noise filtering, graceful degradation, and telephony reliability. The platforms that make shipping a production voice agent as straightforward as deploying a web app will capture enormous developer adoption.
Third, edge and on-device deployment will unlock multiple industries. Healthcare, financial services, and government – some of the largest addressable markets for voice AI – have strict data residency and privacy requirements. Consumer applications and many B2B applications that have on-device needs require smaller models that can run on CPUs. Some voice applications need to function in areas without internet. On-device and on-premise voice models with aggressive quantisation now achieve speech quality within 10% of server-grade accuracy. Cartesia’s Sonic-3 at 40ms TTS latency is a preview of what becomes possible when inference moves to the edge. For regulated industries where data cannot leave the premises, this removes a fundamental adoption blocker.
***
If you’re building in voice AI – whether at the infrastructure layer, the orchestration layer, or the application layer – we’d love to hear from you.
You can find us at shamillah@dawncapital.com and atiyu@dawncapital.com.
Listen to this article (powered by Runware)

